人工智能赋能的数据管理技术研究阅读笔记
代价模型
对执行相同的查询有很多不同方式,通过代价模型估算每种方式的开销,选择开销小的方式。
总代价=IO代价+CPU代价=P*a_page_cpu_time+W*T- P:页面数
- a_page_cpu_time:每个页面读取的IO时间
- W:权重因子,分析每个元组的时间。W的选择方法有很多,看不太懂。
- T:元组数
启发式规则
启发式算法(heuristic algorithm)是相对于最优化算法提出的,是一个基于直观或经验构造的算法。在逻辑查询优化阶段和物理查询优化阶段,都有一些启发规则可用。启发式方法不能保证找到最好的查询计划。PostgreSQL、MySQL和Oracle等数据库在实现查询优化器时,采用了启发式和其他方式相结合的方式
启发式是根据已知可优化规则,对SQL语句做出语义等价转换的优化,或者基于经验对某个物理操作进行改进(如物化操作)。
在物理查询优化阶段常用的启发式规则如下:
- 关系R在列X上建立索引,且对R的选择操作发生在列X上,则采用索引扫描方式。
- R连接S,其中一个关系上的连接列存在索引,则采用索引连接且此关系作为内表。
- R连接S,其中一个关系上的连接列是排序的,则采用排序进行连接比Hash连接好。
排序连接:
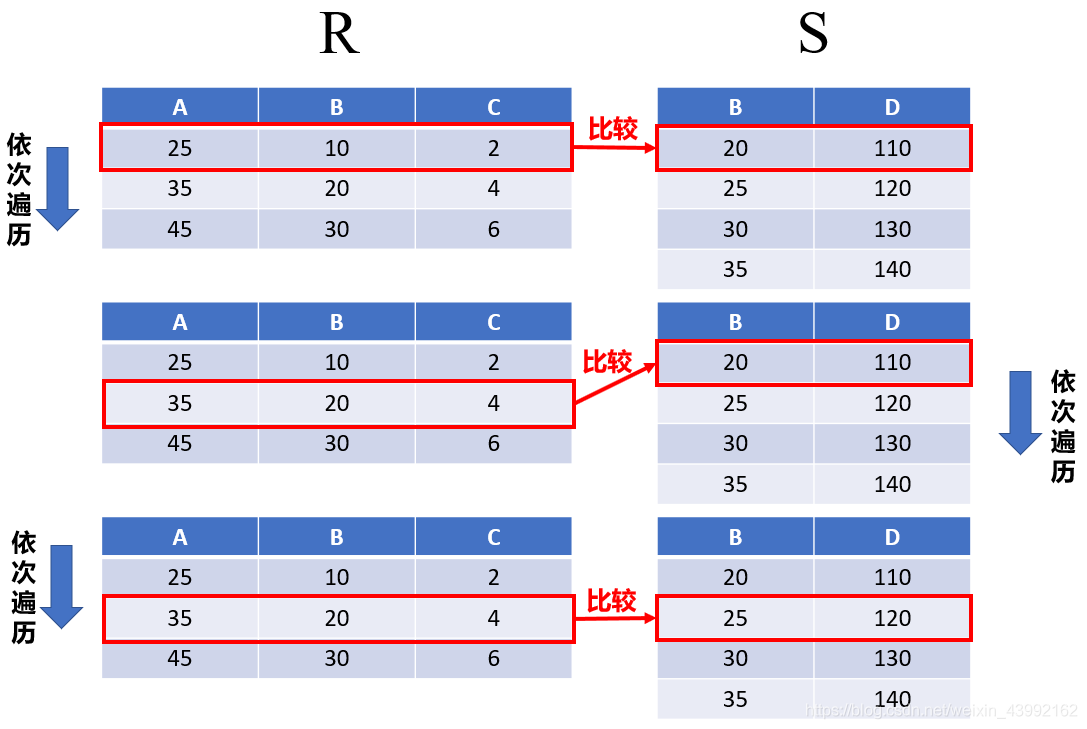
索引连接:在大表上建立小表的索引
哈希连接:用哈希值把两个表分类,遍历大表找小表中哈希值相同的元祖,内存需要能装得下整个小表
人工智能赋能的数据库运维
查询负载预测
其实就是要挑合适的索引和cache
- 离线调优:视图物化(类似cache),索引推荐。根据数据本身的特征预测
- 在线调优:根据实际查询的应用预测
- 根据实时的负载变化调整索引(COLT),考虑负载变化的周期性和幅度
- 根据查询语句的特征对负载进行分类(N-gram模型)
- QueryBot5000 系统利用各种查询的到达率(arrivall rate)做聚类,然后根据每个聚类中查询的平均访问次数来训练预测模型.QueryBot5000
数据库配置参数自调优
数据库参数,不独立,不通用,不标准。一开始的研究只侧重于调整一项参数,比如缓冲区大小。后来支持调整多项参数,但仍然离不开人的参与,需要DBA去定义参数之间的关系。再后来就开始机器学习参数了,不同的参数对应不同的数据库性能,高斯初始化,梯度下降法优化。
云数据库配置的参数量过大,而且样本少。CDBtune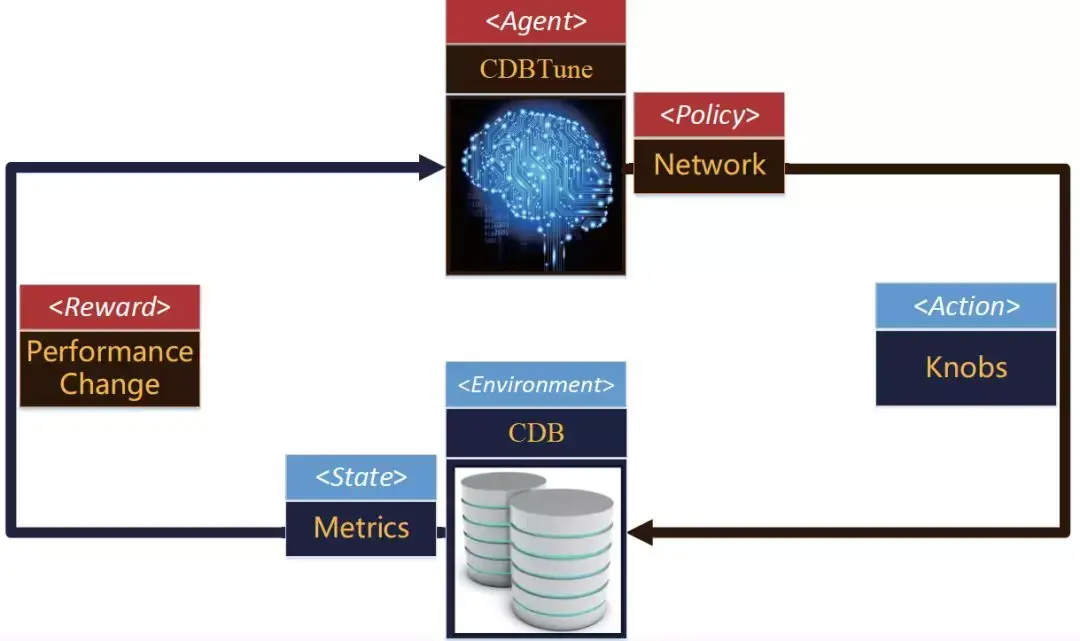
人工智能赋能的数据存取
数据分区优化
分行或者分列。
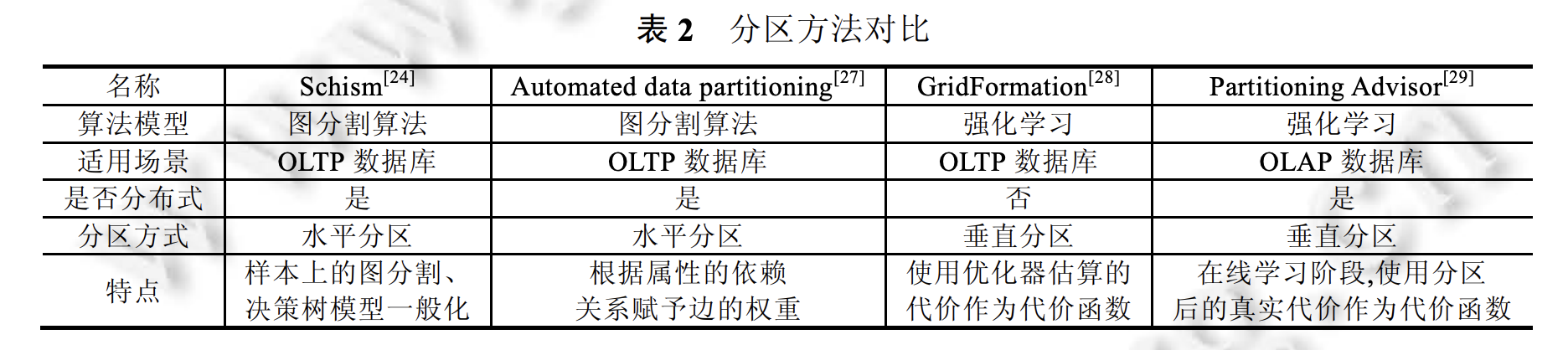
- Schism(分行):图分割,节点代表采样元组,边代表事务。尽量减少跨节点事务。用决策树把其余的内容归并进分好的区里。后来有人给边加权重,为独立事务分配尽量小的权重(ADP)。
- 分列:强化学习探索较优解(离线+在线)。
索引结构
索引可以加快数据库中数据的检索速度,但是建立和维护常见的索引结构通常需要消耗大量的时间和空间资源.文献指出,索引可以作为一种用来定位数据在存储中位置的模型,而这种模型完全可以由机器学习的技术来构建,即 Learned Index.该文解释了如何在了解数据分布的情况下,用 Learned Index 进行范围索引、点索引和存在性索引.传统范围索引的代表是 B 树,而将索引视为模型的时候,键(key)为输入,对应键的记录位置作为预测输出,保证它的最大误差小于一个内存页即可,B 树中的页大小(PageSize)即相当于机器学习模型中的最小/最大误差(min-/max-error).
布隆过滤器:bitmap
索引推荐
一开始是单列索引,后来开始推荐多列索引。
离线推荐:
文中索引推荐算法的核心思想是:如果一个索引不在某个查询的最优索引配置中,那它就不可能在整个工作负载的最优索引配置中.系统从单个查询的单个索引开始迭代,寻找整个负载下的最佳索引配置.
在线推荐:根据实时负载,“What if”在某些列上建立索引。后来“What if”开始用预测函数代替,每过N次查询,就会考虑一次是否要进行一轮调优。
但发现得先去研究一下强化学习是怎么搞的,待续。