Dannet论文
标题:一个一步到位的领域迁移网络,用于无监督的夜视场景语义分割
Abstract
夜视场景语义分割因为光照条件差,且缺乏人工标注的数据集所以一直是一个难题。本文提供了一个可以不使用人工标注的数据集就可以训练的夜视场景语义分割网络。它使用了一个有标注的白天数据集,和一个未标注的数据集(其中包括很多对相同场景的白天夜晚对应的图片)来进行对抗式学习。对于每一个白天-夜晚pair,先在白天的图片上进行分割,得到的结果来监督训练分割夜晚场景。我们还设计了一个重新调整权重的策略,去解决白天夜晚图片本身的不匹配和对于白天图像分割的失误,同时增强了对小物件的识别。DANNet并不会再去训练一个单独的网络来转换白天黑夜的图片作为预处理,他是一个一步到位的网络。
1 Introduction
前人尝试过的策略:
- 使用一个黄昏数据集作为白天到夜晚的桥梁
- 单独训练一个网络来转换白天和黑夜的图片
共同的缺点:
- 都要很麻烦的预处理。
- 使得迁移之后训练的结果高度依赖于迁移之前的领域
Cityscapes:有很多标注好的白天数据集
Dark Zurich-D:没有标注的白天数据集
Dark Zurich-N:没有标注的夜晚数据集
Dark Zurich-D和Dark Zurich-N中的图片可以一一配对。
所以就先用Cityscapes训练好的model应用到Dark Zurich-D上,得到的结果用于监督Dark Zurich-N上的训练。
然后我们用了一个relighting网络先让不同领域之间的图片尽量相近一些,然后再对这些图片使用相同的分割网络进行分割。最后在输出的时候使用一个对抗学习。
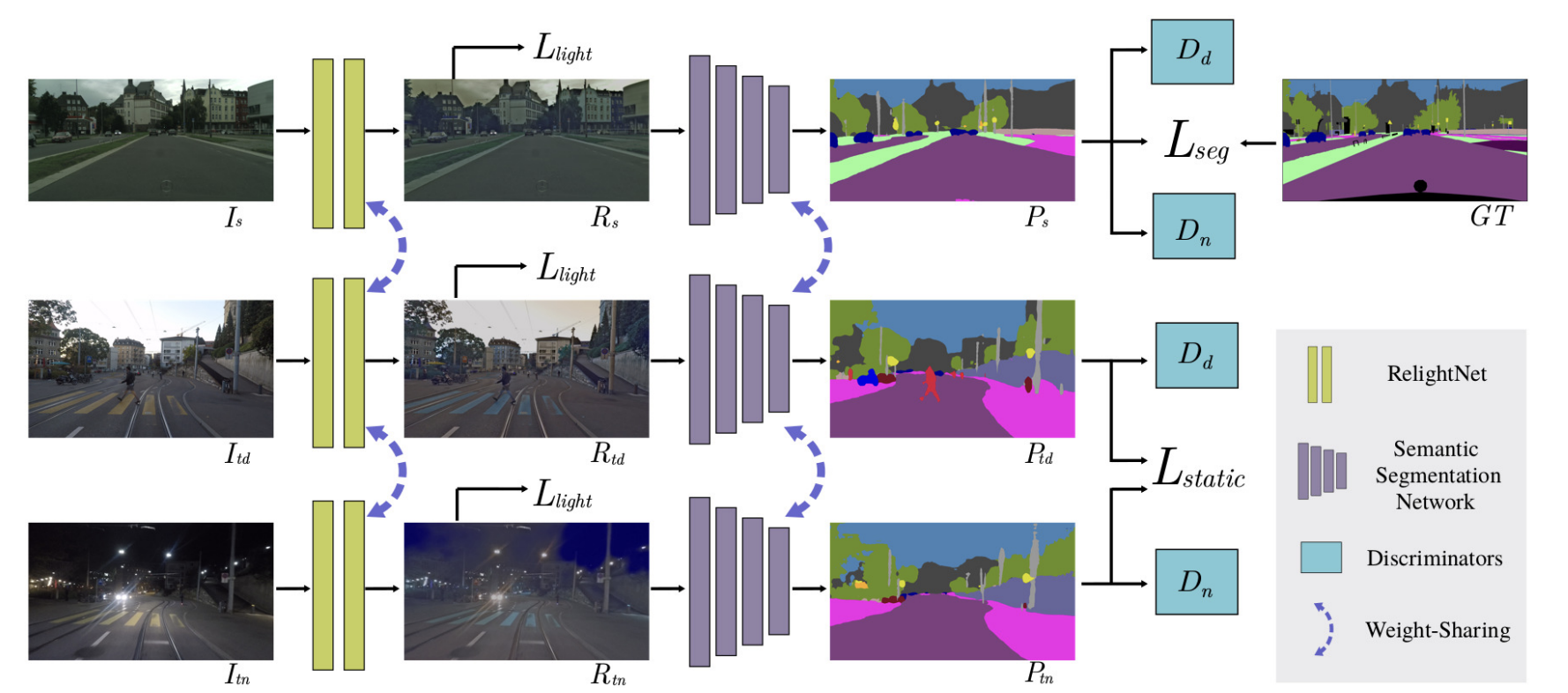
$I_s,I_{td},I_{tn}$就是分别从Cityscapes和Dark Zurich-D和Dark Zurich-N中取的。然后他们三个图片统一经过一个同一个重光照网络之后变得更像了,这一步都使用的是$L_{light}$。然后再都经过同一个分割网络产生分割结果。这一步不同的地方在于:
- 从$I_s$来的图片有ground truth,可以直接使用ground truth算loss进行训练
- 从$I_{td}$和$I_{tn}$来的图片没有ground truth,他们两个首先会在图像优化方面(比如让图片更清晰,对小物件识别灵敏度更高)上共用一个$L_{static}$的loss,这个loss和分类的正确性无关。然后同时也把结果输出给两个discrimminator($D_d$和$D_n$),让他们去评判输出的结果到底是从$I_s$出来的,还是从$I_{td}$和$I_{tn}$出来的。这样做最后达到的效果就是,图像质量本身品质又高,又像是从$I_s$来的一样。
discriminator是怎么工作的?